“字符与编码”是一个被经常讨论的话题。即使这样,时常出现的乱码仍然困扰着大家。虽然我们有很多的办法可以用来消除乱码,但我们并不一定理解这些办法的内在原理。而有的乱码产生的原因,实际上由于底层代码本身有问题所导致的。因此,不仅是初学者会对字符编码感到模糊,有的底层开发人员同样对字符编码缺乏准确的理解。
一、相关概念的理解
0、字符/字节/字符串
| 概念描述 | 举例 | |
|---|---|---|
| 字符 | 人们使用的记号,抽象意义上的一个符号。 | '1', '中', 'a', '$', '¥', …… |
| 字节 | 计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间。 | 0x01, 0x45, 0xFA, …… |
| ANSI 字符串 | 在内存中,如果“字符”是以 ANSI 编码形式存在的,一个字符可能使用一个字节或多个字节来表示,那么我们称这种字符串为 ANSI 字符串或者多字节字符串。 | "中文123" (占7字节) |
| UNICODE 字符串 | 在内存中,如果“字符”是以在 UNICODE 中的序号存在的,那么我们称这种字符串为 UNICODE 字符串或者宽字节字符串。 | L"中文123" (占10字节) |
1、什么是字符集
在介绍字符集之前,我们先了解下为什么要有字符集。
我们在计算机屏幕上看到的是实体化的文字,而在计算机存储介质中存放的实际是二进制的比特流。
那么在这两者之间的转换规则就需要一个统一的标准,为了实现转换标准,各种字符集标准就出现了。
简单的说字符集就是规定了某个文字对应的二进制数字存放方式(编码)和某串二进制数值代表了哪个文字(解码)的转换关系。
那么为什么会有那么多字符集标准呢?
很多规范和标准在最初制定时并不会意识到这将会是以后全球普适的准则,或者处于组织本身利益就想从本质上区别于现有标准。
于是,就产生了那么多具有相同效果但又不相互兼容的标准了。
说了那么多我们来看一个实际例子,下面就是屌这个字在各种编码下的十六进制和二进制编码结果,怎么样有没有一种很屌的感觉?
| 字符集 | 16进制编码 | 对应的二进制数据 |
|---|---|---|
| UTF-8 | 0xE5B18C | 1110 0101 1011 0001 1000 1100 |
| UTF-16 | 0x5C4C | 1011 1000 1001 1000 |
| GBK | 0x8CC5 | 1000 1100 1100 0101 |
字符集:文字编码解码关系的定义,英语这种字符中的 water 和汉语这种字符中的水是指同一个东西。
2、什么是字符编码
字符集只是一个规则集合的名字,对应到真实生活中,字符集就是对某种语言的称呼。例如:英语,汉语,日语。
规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“字符编码”。
3、ASCII 码
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。
也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
4、非ASCII 码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
比如在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。
比如130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。
但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
5、Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。
因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
6、Unicode 的问题
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题:
第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。
2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
7、UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。
如果一个字节的第一位是0,则这个字节单独就是一个字符;
如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
Unicode就是上文中提到的字符集,而UTF-8就是字符编码,即Unicode规则字库的一种实现形式。
二、容易产生的误解
| 对编码的误解 | |
|---|---|
| 误解一 | 在将“字节串”转化成“UNICODE 字符串”时,比如在读取文本文件时,或者通过网络传输文本时,容易将“字节串”简单地作为单字节字符串,采用每“一个字节”就是“一个字符”的方法进行转化。 而实际上,在非英文的环境中,应该将“字节串”作为 ANSI 字符串,采用适当的编码来得到 UNICODE 字符串,有可能“多个字节”才能得到“一个字符”。 通常,一直在英文环境下做开发的程序员们,容易有这种误解。 |
| 误解二 | 在 DOS,Windows 98 等非 UNICODE 环境下,字符串都是以 ANSI 编码的字节形式存在的。这种以字节形式存在的字符串,必须知道是哪种编码才能被正确地使用。这使我们形成了一个惯性思维:“字符串的编码”。 当 UNICODE 被支持后,Java 中的 String 是以字符的“序号”来存储的,不是以“某种编码的字节”来存储的,因此已经不存在“字符串的编码”这个概念了。只有在“字符串”与“字节串”转化时,或者,将一个“字节串”当成一个 ANSI 字符串时,才有编码的概念。 不少的人都有这个误解。 |
第一种误解,往往是导致乱码产生的原因。第二种误解,往往导致本来容易纠正的乱码问题变得更复杂。
在这里,我们可以看到,其中所讲的“误解一”,即采用每“一个字节”就是“一个字符”的转化方法,实际上也就等同于采用 iso-8859-1 进行转化。因此,我们常常使用 bytes = string.getBytes("iso-8859-1") 来进行逆向操作,得到原始的“字节串”。然后再使用正确的 ANSI 编码,比如 string = new String(bytes, "GB2312"),来得到正确的“UNICODE 字符串”。
三、乱码产生的原因和解决办法
简单的说乱码的出现是因为:编码和解码时用了不同或者不兼容的字符集。
要从乱码字符中反解出原来的正确文字需要对各个字符集编码规则有较为深刻的掌握。但是原理很简单,这里用最常见的UTF-8被错误用GBK展示时的乱码为例,来说明具体反解和识别过程。
第1步 编码
假设我们在页面上看到寰堝睂这样的乱码,而又得知我们的浏览器当前使用GBK编码。那么第一步我们就能先通过GBK把乱码编码成二进制表达式。当然查表编码效率很低,我们也可以用以下SQL语句直接通过MySQL客户端来做编码工作:
mysql [localhost] {msandbox} > select hex(convert('寰堝睂' using gbk));
+-------------------------------------+
| hex(convert('寰堝睂' using gbk)) |
+-------------------------------------+
| E5BE88E5B18C |
+-------------------------------------+
1 row in set (0.01 sec)
第2步 识别
现在我们得到了解码后的二进制字符串E5BE88E5B18C。然后我们将它按字节拆开。
| Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|
| E5 | BE | 88 | E5 | B1 | 8C |
第3步 解码
然后我们就能拿着E5BE88E5B18C用UTF-8解码,查看乱码前的文字了。当然我们可以不查表直接通过SQL获得结果:
mysql [localhost] {msandbox} ((none)) > select convert(0xE5BE88E5B18C using utf8);
+------------------------------------+
| convert(0xE5BE88E5B18C using utf8) |
+------------------------------------+
| 很屌 |
+------------------------------------+
1 row in set (0.00 sec)
四、字符编码工作方式
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
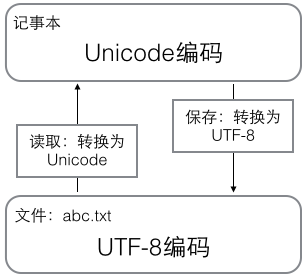
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
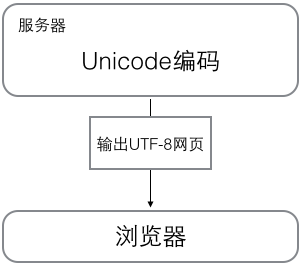
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
五、常见问题处理之Emoji
所谓Emoji就是一种在Unicode位于\u1F601-\u1F64F区段的字符。这个显然超过了目前常用的UTF-8字符集的编码范围\u0000-\uFFFF。Emoji表情随着IOS的普及和微信的支持越来越常见。
下面就是几个常见的Emoji:  那么Emoji字符表情会对我们平时的开发运维带来什么影响呢?
那么Emoji字符表情会对我们平时的开发运维带来什么影响呢?
最常见的问题就在于将他存入MySQL数据库的时候。一般来说MySQL数据库的默认字符集都会配置成UTF-8(三字节),而utf8mb4在5.5以后才被支持,也很少会有DBA主动将系统默认字符集改成utf8mb4。
那么问题就来了,当我们把一个需要4字节UTF-8编码才能表示的字符存入数据库的时候就会报错:ERROR 1366: Incorrect string value: '\xF0\x9D\x8C\x86' for column 。 如果认真阅读了上面的解释,那么这个报错也就不难看懂了。我们试图将一串Bytes插入到一列中,而这串Bytes的第一个字节是\xF0意味着这是一个四字节的UTF-8编码。
但是当MySQL表和列字符集配置为UTF-8的时候是无法存储这样的字符的,所以报了错。 那么遇到这种情况我们如何解决呢?
有两种方式:升级MySQL到5.6或更高版本,并且将表字符集切换至utf8mb4。
第二种方法就是在把内容存入到数据库之前做一次过滤,将Emoji字符替换成一段特殊的文字编码,然后再存入数据库中。
之后从数据库获取或者前端展示时再将这段特殊文字编码转换成Emoji显示。
第二种方法我们假设用-*-1F601-*-来替代4字节的Emoji,那么具体实现python代码可以参见Stackoverflow上的回答